

From AI Outfit to Add to Cart: Making AI-Generated Fashion Looks Shoppable at Scale
TL;DR
LookSync is Glance's production system for making AI-generated fashion looks instantly shoppable — matching outfit items from 18M+ catalog products against 350K+ AI-generated looks per day at sub-second latency.
This post explains how it works in plain language: the two-part retrieval and reranking architecture, how AI looks are decomposed into layer-wise shopping intent, and how sub-second response time is achieved at scale.
The full technical paper won Best Paper Award at CODS 2025 and is available on arXiv.
At Glance, we've been building towards a simple but ambitious idea: what if shopping felt as effortless as inspiration? That question sits at the heart of everything we do with Glance, and it's what led us to the problem this post is about.
If you've ever seen an outfit online and thought, I need this look, you've also hit the next wall:
Where do I buy it?
Now imagine the outfit was generated by AI. It looks real. It looks stylish. But it might be a blend of inspirations that doesn't exist as a single real product in any retailer catalog.
That's the gap we set out to bridge, and closing it matters because uninspired browsing is the enemy of conversion. If a user falls in love with an AI-generated look but can't shop it, we've created desire without delivery. That's bad for users and bad for the business. Making every AI look instantly shoppable was, for us, not just a research problem, it was a product imperative.
This post is intentionally written as a layman's view. If you want the full architecture, evaluations, model comparisons, and system specifics, please refer to our paper — link at the end.
The Problem

We want to take an AI-generated fashion look and make it instantly shoppable by finding real products — shirts, pants, shoes, accessories — that match the look closely enough that a user feels, Yep. That's basically it.
Not sort of similar. Not same color but totally different vibe. Actually wearable and convincing alternatives.
In our production setting as of today, this system needs to handle:
- 18M+ catalog products
- 350K+ AI looks per day
- sub-second response time while serving
That's not just a research prototype, it's a system that works every day.
Why This Is Harder Than Image Search
Most people hear "visual search" and assume the answer is: embed image → find nearest neighbors → done.
That gets you close… but not close enough.
Fashion similarity is weirdly human:
- A shirt can match color but fail on fabric.
- Pants can match category but fail on fit.
- Shoes can match silhouette but feel off stylistically.
And with AI-generated images, the challenge gets even sharper: the image may include details that are slightly unreal — textures, patterns, or combinations that don't exist in inventory. Our job becomes: find the best real-world approximation, reliably.
The System Behind the Magic: LookSync
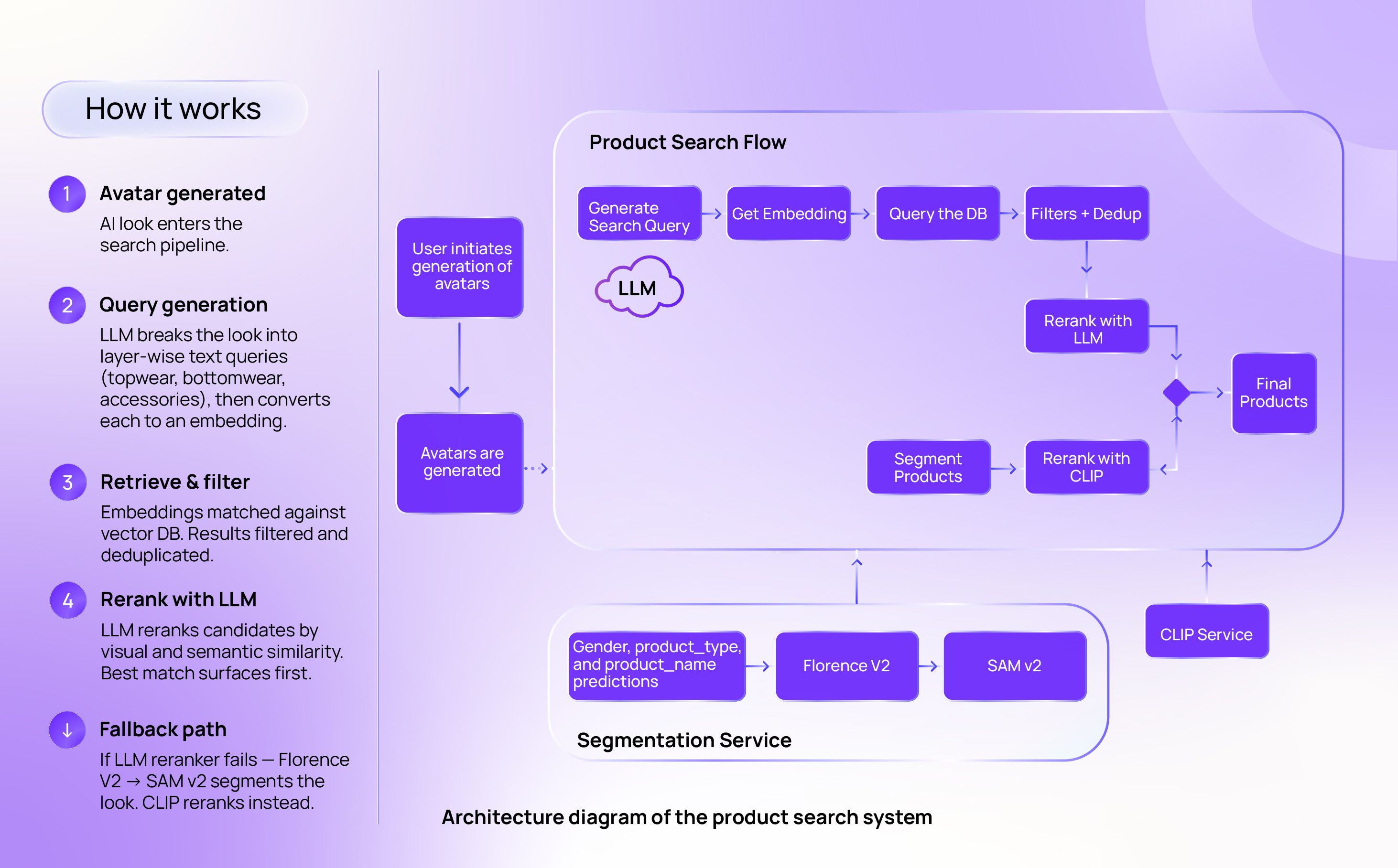
At a high level, LookSync is a two-part machine:
- 1) The catalog brain — It constantly ingests product data from multiple sources, cleans it, standardizes it, and indexes it so we can search fast.
- 2) The query brain — When an AI look comes in, it quickly figures out what the look contains, searches the catalog, and then reranks results so the top matches feel right.
This is the key theme:
Retrieval gets you close. Reranking makes it feel right.
Here's how Ritesh, Pradeep, Muthu, Ian, and the team actually built this, step by step.
Step 1: Preparing the catalog
We ingest product feeds continuously. Whenever products are added or updated, they flow through a pipeline where we:
- normalize messy metadata (categories, gender, etc.)
- generate compact "visual fingerprints" (embeddings) for product images
- store these embeddings in a vector database so we can retrieve visually similar items quickly
We also use Redis for caching standardized attributes and reducing repeated lookups.
The result: a catalog that's searchable by visual meaning, not just keywords.
Step 2: Turning an AI look into a searchable intent
Here's a surprising insight: searching with the whole outfit image isn't enough.
Outfits are multi-item. People don't shop an outfit. They shop:
- a shirt
- jeans
- shoes
- a watch
So we first convert the AI look into layer-wise descriptions using an LLM — essentially asking: "What's the topwear? What's the bottomwear? Accessories? Describe them precisely."
Example descriptions include details like collar type, sleeve length, fit, wash, and accessory attributes. One such example would be:
{ "outermost_topwear": "Men's charcoal grey polo shirt, solid, button-down collar, long sleeves, straight hem, casualwear.", "bottomwear": "Men's indigo blue denim jeans, solid, straight leg, medium wash, five-pocket styling, casualwear.", "accessory_1": "Men's silver wristwatch, round face, metal band, analog display, everyday wear." }
Now we have something powerful: a structured shopping intent per layer.
Step 3: Fast retrieval
Once we have a query representation, we perform similarity search in the vector database to pull top candidates fast, then:
- deduplicate near-identical items
- apply practical filters where needed
At this stage, results are typically "close." But "close" can still disappoint.
Step 4: Reranking
This is where we go from "similar" to "shop-worthy." After retrieval, we rerank candidates using an LLM so the top results align better with fine-grained attributes and the overall vibe.
And because production systems need to be resilient, we also built a fallback reranking approach: if the LLM reranker fails, we fall back to segmentation + embedding similarity reranking.
The outcome is simple from a user perspective: the first few products actually look like what they wanted.
Serving: How We Reach Sub-Second Latency
At scale, latency isn't won by a single fast model. It's won by system discipline.
What helped us hit under 1 second latency for P90, while serving 350K+ AI looks per day on an 18M+ product index, was a simple principle:
Do the heavy work ahead of time. Keep serving lightweight. Cache aggressively. Plan for failures.
Think of it like a restaurant:
- The offline pipeline is the kitchen doing prep work early.
- The online system is the counter: fast, predictable, and optimized for quick serving.
Offline Pipeline
Offline jobs handle the heavy lifting:
- continuous ingestion + metadata enrichment
- embedding generation for new products
- retagging products so they're easy to fetch during shop this look
- storing those precomputed outputs in a fast store (we cache these in Bigtable)
This caching is a big deal because it reduces both cost and latency — we're not recomputing the same things repeatedly.
Online (stay intentionally thin)
Online serving does as little as possible:
- accept the shop this look request
- retrieve the cached predictions/results
- respond quickly back to the user
That's it.
This separation is what keeps the system consistent and stable as we scale: the online path stays fast because it's mostly fetch + respond, not compute + think.
How We Know It Works (Because "looks right" Is Subjective)
Fashion matching isn't a single metric. People evaluate color, fit, pattern, fabric impression, and overall style coherence.
So we rely on human judgment (Mean Opinion Score) to evaluate different modeling choices and ensure improvements are real, not just theoretical.
What The User Experiences
All of this complexity collapses into a simple flow in Glance:
- User generates an AI look
- Taps shop this look
- Sees matching products (topwear, bottomwear, accessories, etc.)
- Clicks through to product pages with price, sizes, availability
That's the bar: fast, relevant, shoppable.
Why We Think This Matters
AI can generate endless inspiration. Retail inventory is finite. The real challenge — and what I'm most proud of this team for solving — is building the bridge between infinite creative generation and real-world product availability. LookSync is our production answer to that problem: a system that scales to millions of products, handles hundreds of thousands of AI looks daily, and returns results fast enough to feel instant. That it earned a Best Paper Award at CODS 2025 is a reflection of the rigour Ritesh, Pradeep, Muthu, and Ian brought to the work. For context on how this fits into Glance's broader AI fashion discovery approach, see how the full pipeline works from selfie to styled look.
Want the full technical deep dive?
This blog is the layman-friendly story of the work. For the full details — architecture diagrams, model choices, evaluations, and implementation specifics — read the paper: arxiv.org/pdf/2511.00072.
FAQs
1. How does Glance match AI-generated outfit looks to real shoppable products?
Glance uses a system called LookSync — a two-part retrieval and reranking architecture. An AI look is first decomposed into layer-wise descriptions using an LLM, identifying topwear, bottomwear, shoes, and accessories separately. Each layer is then searched against a vector database of 18M+ catalog products using visual embeddings. A reranking step using an LLM refines results from visually similar to shop-worthy — aligning fine-grained attributes like collar type, fabric impression, and overall style coherence. The system handles 350K+ AI looks per day at sub-second latency.
2. What is LookSync and why did Glance build it?
LookSync is Glance's production system for bridging AI-generated fashion inspiration and real-world product availability. AI can generate endless outfit looks — but if those looks aren't instantly shoppable, desire is created without delivery. LookSync solves this by decomposing AI looks into structured shopping intent per garment layer, retrieving the closest real products from a catalog of 18M+ items, and reranking results so the top matches feel right.
3. How does Glance achieve sub-second latency for AI fashion matching at scale?
Glance separates heavy computation from serving. An offline pipeline handles catalog ingestion, embedding generation, and product retagging ahead of time — results are cached in Bigtable. The online serving layer does as little as possible: accept the request, retrieve cached results, respond. This keeps the online path fast because it is mostly fetch and respond rather than compute and think. The result is sub-second P90 latency while serving 350K+ AI looks per day against an 18M+ product index.

Download the Glance app now


